一些术语
SMP
SMP(Symmetric Multi-Processors), 对称多处理器,这是一种总线结构,描述了各个CPU、共享内存、总线之间的沟通方式。技术实现来源于CPU内部的 IO APIC可以处理IO中断,还有一个自己的CPU APIC处理, APIC是高级可编程中断控制器。
Bus(总线)
总线,用于计算机各个组件数据通信,分为数据总线,地址总线和控制总线。 总线的传输速度单位带宽=频率(Ghz)*位宽度/8
在linux里面
bus相关的信息在/sys/bus目录
QPI(Quick Path Interconnect)
快速通道互联,用于替代FSB(Front Side Bus),20位宽的QPI通道带宽更大可达25.6GB/s以上,效率更高 FSB是前端总线,用于连接北桥和CPU,前端总线带宽可能会随着显卡速度和内存频率等快速成长成为瓶颈 QuickPath其实是位于I/O controller和cpu之间的通道结构 intel page
{kind=link}
core,die
cpu核心, 一般分为物理核心physical core和逻辑核心logic core
一般我们说几U对应的是服务器有几个CPU,
说24个物理核,对应的是core
说支持48线程对应logic core,逻辑核是cpu通过超线程技术虚拟出来的
die,cpu里面的内部结构,这个是硬件工程师喜欢说的概念,die是一种晶圆结构,一个或者多个die组成一个cpu,
一个die里面可能有若干个core, 可以看到一个die中可以共享L3 cache
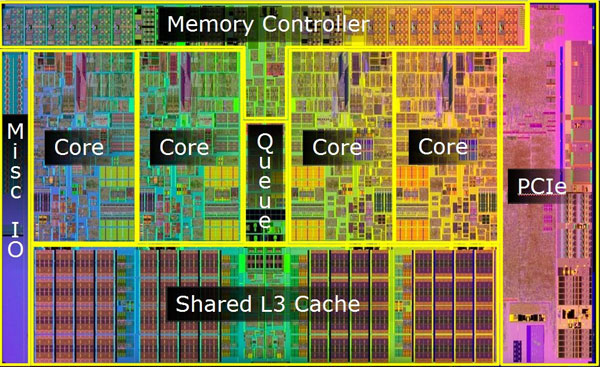 ◎ ../../images/cpu-die.jpg
linux中,cpu信息很容易可以看到cat /proc/cpuinfo或者lscpu
◎ ../../images/cpu-die.jpg
linux中,cpu信息很容易可以看到cat /proc/cpuinfo或者lscpu
|
|
NUMA是什么
UMA(Unified Memory Access)是什么
了解NUMA前,先看UMA是什么,顾名思义,UMA是统一内存访问,即系统CPU统一共享所有物理内存,举个例子,就是公共图书馆,大家都享有图书资源
NUMA
在共享内存架构(Shared memory architecture)下,还有一种是NUMA(Non-Unitifed Memory Access), 意思大家还是共享的,但是要看你是哪个学院的, 如果你是计算机学院的,那么借计算机的书只需要去院里的图书点领取即可,如果是借其他部门或者公共的资源,就需要跨单元,走到另一个学院才能借到 这里的学院是numa node, 而同学相当于CPU, 图书资源是内存,而走向图书资源的路是总线,走向其他资源的是QPI
NUMA的背景
NUMA为什么后来被提出来呢? 之前,在零几年和以前,其实计算机的核心数并不算多,大家在向着高Hz(说白了就是速度)发展,而那个时候总线带宽的速度是ok的,所以大家一致把内 存当成公共内存使用没有问题,而当现在cpu核心服务器动辄48逻辑核的情况下,对于内存的吞吐量和延迟都有很高的要求,这个时候问题来了,多个程序 如果都同事调用了多个cpu执行代码,对于内存的使用可能会影响,因为总线带宽是有限的,在大家都平等的情况下跑满带宽,而有了NUMA呢,可以为程序 分配内存,这些内存大部分情况是本地内存,也可以访问但时间远远大于本地内存的远程内存。
Linux NUMA
我们已经知道NUMA是为了提高CPU和内存之间的I/O能力而提出来的,但是NUMA有个问题就是访问其他NUMA node节点的内存,也就是跨CPU跨NUMA节点的时候, 通常时间就会大大拉长,甚至比使用SMP结构的时间长,所有线上业务就存在某些场景禁用numa的情况
linux numa文档
有必要先看下这篇文档https://www.kernel.org/doc/html/v4.18/vm/numa.html, 在继续看 我简单翻译下主要内容: NUMA的视角可以分为硬件层面和linux的软件层面,numa是一种系统架构,这个架构由cpu(1或多个),memory,I/O buses组成,为了方便,用cell来标识硬件 在软件层面的抽象。每个cell其实内部可以看成是原来我们的SMP系统结构,NUMA里面的各个cell通过system inteconnect(QPI)或者crossbar来连接,这些互联组件 可以创建带有多个cell的NUMA系统。 对于Linux,关注于两种NUMA结构的实现(Cache Coherent NUMA or ccNUMA)。ccNUMA所有内存对CPU是可见的,而cached coherent则是通过硬件处理,这些硬件 通常是处理器缓存或者系统互联。 NUMA的同一cell之间对内存的访问非常快,而如果是其他cell,则慢得多,但是都能访问。 制造商不会制造NUMA软件系统让软件工程师好过,尽管这是为了提高内存带宽和访问速度。为了获取更加弹性稳定的内存带宽,软件需要保证大量的内存需要在 本地cache里面,高命中率,或者是就近的cell中获取。 Linux对硬件资源做了一层抽象,叫nodes,和cell构成映射关系。一个node可能包含一个或多个cpu,内存,I/O buses。再次说明,较近的node之前获取内存会比 远的要快很多。 在一些架构中,比如x86, Linux会隐藏没有绑定内存的cell的node节点。而且会把绑定到那个cell的CPU所在的node放到一个有内存的node中。而且在这些体系结构中, 不能够指望一个node的所有CPU都有相同的内存带宽和访问时间。这里意思应该是对资源访问永远不可能做到绝对平等。 另外,还比如在类似x86的系统中,Linux允许虚拟另外的nodes。这样就可以在非NUMA系统中进行测试。 对于每一个node下的内存,Linux做了分区,zone(DMA,DMA32,NORMAL,HIGH_MEMORY,MOVABLE),如果一个zone对于一个请求没有可用空间,这种情况叫overflow或者 fallback。 默认情况下Linux会从node里面找zone找内存,但是如果没有,就得去相邻的找。 Linux的调度系统会尽量少的像远程node分配资源,并且在分配不平衡的情况下可以node层面做一些数据迁移。 对于系统管理员和应用开发者,可以使用taskset和numactl来通过改变不同的cpu亲和性提高numa本地化。也可以通过程序接口sched_setaffinity。甚至可以直接修改 NUMA的内存分配策略,参见../../files/numa_memory_policy.rst。 系统管理员可以通过cgroup和cpusets来限制非特权用户对于numa的使用,参见内核文档../../files/cpusets.txt。 有时候在一些分配场景,不能容忍fallback这种行为。那么当分配失败时候,有些系统会只用cpu所在node的,如果分配失败则进入fallback,对于slab的内存分配器是 这样,而有些子系统则disable当不能分配,对于kernel profiling子系统是这样。
taskset
numactl
参考文档
- UMA https://baike.baidu.com/item/%E7%BB%9F%E4%B8%80%E5%86%85%E5%AD%98%E8%AE%BF%E9%97%AE/8567607?fromtitle=UMA&fromid=12800502#viewPageContent
- NUMA https://www.kernel.org/doc/html/v4.18/vm/numa.html
- SMP https://baike.baidu.com/item/%E5%AF%B9%E7%A7%B0%E5%A4%9A%E5%A4%84%E7%90%86/6274908?fromtitle=SMP&fromid=235768&fr=aladdin
- Bus https://baike.baidu.com/item/%E6%80%BB%E7%BA%BF/108823?fromtitle=BUS&fromid=3827864
- QPI https://zh.wikipedia.org/wiki/%E5%BF%AB%E9%80%9F%E9%80%9A%E9%81%93%E4%BA%92%E8%81%94
- QuickPath https://www.intel.com/content/www/us/en/io/quickpath-technology/quickpath-technology-general.html