Linux Processes & Threads (linux进程和线程)
进程和线程
什么是进程(process)?
在linux中,也称为task,是计算机程序代码的一次执行,同时包含执行时候的其他资源,比如 挂起的信号,处理器状态,内核内部数据,内存地址空间映射等。 什么是线程(thread)? 在linux中,线程是共享一些资源的进程,每个线程包含一个独立的程序计数器,进程栈和一组进 程寄存器,内核调度的对象是线程。
父进程和子进程
linux通过调用fork()创建进程,调用fork的是父进程,fork()产生的是子进程。 fork()通过复制现有进程产生一个新进程。 调用结束后,父进程恢复执行,子进程开始执行。 fork()系统调用从内核返回两次,一次回到父进程,另一次回到新产生的子进程。这里可以man fork 看下,如果创建成功,会从子进程返回0,从父进程返回创建的PID,创建失败,父进程返回-1,并且errno 被设置。
进程描述符和其结构
- Linux把进程的列表存放于任务队列的双向循环链表中,链表中每一项都是task_struct, 称为进程
描述符Process Descriptor(PD),位于include/linux/sched.h 代码这里我不截取了,太长了, 主要是大量的编译判断,和对应的配置, 一个pd文章介绍32位机器上达到 1.7KB,pd里面主要包含打开的文件,进程的地址空间,挂起的信号,进程的状态,父进程等等
- 进程描述符通过slab进行分配,熟悉linux的都知道slabtop可以看各种分配信息,包括dentry等
这样便于task_struct复用和缓存着色
- 由于寄存器有限等原因,2.16内核之前,task_struct放在进程内核栈的底端方便寻找,而后来加入slab, 把thread info放置在内核栈的最高位(向下增长栈的栈底,向上增长栈的栈顶),这样就可以通过计算 偏移值计算出task_struct的位置
- 由于是双向循环链表,所以可以遍历所有的进程,默认linux支持的进程数可以通过如下命令获取
|
|
这个是标记内核的最大pid值2的16次方,不同系统可能会存在差异 文中介绍了计算task_struct地址的方法 movl $-8192, %eax andl %esp, %eax movl是移动, mov source dst 其中l表示32位长字值的运算,首行表示,$表示获取地址, 把8192传给eax寄存器 and1是与运算 在32位机器上,eax是4字节(32位)寄存器,一般存放加法计算的结果 esp是寄存器,用于存放栈顶指针,把栈顶指针的值和这个地址相与 其实就是让栈顶指针地址这个值的后13位置0 这里其实是假定栈的大小是8KB,所以每一个栈底就是抹掉后13位,就比如有2个栈,那么就是14位的0后13位, 1后13位,怎么表示每个栈底呢,0+13个0,1+13个0,那8192是1后面接13个0 这里比较晦涩的是汇编语言,感觉全还给老师了~
进程状态
相信大家操作系统里面必然会学到进程状态和进程状态的循环,通常进程状态分为,可能有的版本会不一样,但是基本都差不多
- TASK_RUNNING(运行)
- TASK_INTERRUPTIBLE(可中断) 进程正在睡眠(阻塞),等待某个条件的达成。
- TASK_UNINTERRUPTIBLE(不可中断) 接收到信号也不会唤醒或者投入运行外状态与可打断状态相同。raid卡相关命令类似这种D进程不可中断,因为不希望有奇怪的结果发生。
- __TASK_TRACED 被进程跟踪的进程,比如通过ptrace调试的进程
+-----------------+ +-----------------+ +-----------------+ +-----------------+
| | | | schedule() | | | |
| fork() new | forks | task_running +------------------> task_running | do_exit() | task exited |
| process +----------------> (ready) | | +--------------------> |
| | | <------------------+ (running) | | |
| | | | preempt | | | |
+-----------------+ +--------^--------+ +---------+-------+ +-----------------+
| |
| |
| |
| |
| +-----------------+ |
| | | |
| | task | |
+--------+ (interruptible) <----------+
| (un..) |
| |
+-----------------+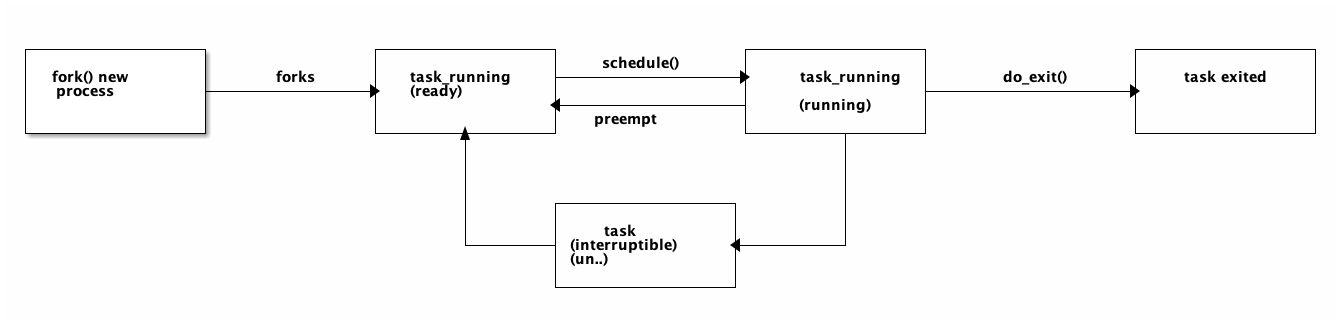 ◎ ../images/threads_states.png
◎ ../images/threads_states.png
进程家族树
大家都知道linux里面是存在PID为1的init进程,linux后面所有的进程都是这个进程的后代。
如果设计过多级结构的都知道,我们需要表示父母和子女。在linux里面这里是parent和children。
|
|
这里的parent和real_parent 可以发现有一个指向parent的结构体指针 同时有两个链表一个是访问子进程的,一个访问姊妹进程的
这里文中讲到了遍历进程树的办法,分别为
|
|
C fork的简单例子
这里具体如何写出一个c下面的例子,是一个值得思考的问题 这里参考下这篇blog
|
|
总结下:
- fork()会返回两次,所以有了两次输出
- getpid(),getppid()用于获取当前进程id和父进程id
- pid -1表示创建进程失败(进程数达到上限EAGAIN或者没有内存分配ENOMEM),pid 0表示当前在子进程,pid为大于0,表示子进程已经返回到父进程,且子进程号是pid
- 返回是随机的,(可以通过在if之间加sleep测试),可能先返回到父进程,也可能先在子进程处理 关于这个可以参考下stackoverflow的讨论
这里很明显会有一个问题,如果我希望子进程先返回,怎么操作呢?
进程创建
一般的系统进程创建首先是分配一段地址,在地址里创建进程,把程序读到新的地址空间,并执行。
linux把进程创建分为两步,fork()和exec()。
fork()函数通过拷贝当前进程创建子进程,子进程和父进程区别在于不同的PID,PPID(设置为父进程的PID),还有一些 资源和统计量(比如挂起的信号等),目测还有一些PC寄存器等。
exec()函数读取可执行程序载入地址空间开始运行。
写时拷贝
传统的fork()直接把所有的资源复制给新创建的进程,相当于全量copy,这样效率比较低下。而且如果新进程打算立即执行新的 代码的话,又要重新拷贝。
linux设计的比较聪明,fork()函数利用copy-on-write技术,也即写时拷贝。内核此时并不复制整个进程内存地址空间,而是和父进程 共用地址空间。只有需要写入的时候,数据才会被复制。在这之前,都是只读方式共享。文中举例当我们fork()之后立即执行exec()就 不需要执行copy了。
linux fork()的开销实际相当于复制父进程的页表和创建一个新的进程标识符。