InfluxDB
InfluxDB
简介
influxdb是一个基于go语言开发的时序数据库,通常用于和时间有关的统计、监控等。 更深入的可以看下知乎这篇文章https://zhuanlan.zhihu.com/p/97247465 官方文档必看https://docs.influxdata.com/influxdb/v1.8/ 官方github https://github.com/influxdata
安装
详情请看https://docs.influxdata.com/influxdb/v1.8/introduction/install/
debian系
|
|
centos系
|
|
准备工作
整体操作和mysql比较类似,但是大部分情况需要注意下大小写等问题。建议先看下官方的get_started
关键概念
https://docs.influxdata.com/influxdb/v1.8/concepts/key_concepts/ 所有术语 https://docs.influxdata.com/influxdb/v1.8/concepts/glossary/
- database
数据库,一个可以放保留策略,连续查询和时间序列数据的容器
- measurement
描述一种数据结构,类似mysql的表
- point
点,一个点对应一个measurement和对应的数据,和mysql的row类似
- retention policy(RP)
生存周期策略,保留多少时间内的数据,保留多少份放到集群内 具体rp相关策略可以参考,这里不再赘述 https://docs.influxdata.com/influxdb/v1.8/query_language/manage-database/#retention-policy-management
- series
一个逻辑的组,这个组包含measurements,tag set and field key
和关系型数据库的对比
https://docs.influxdata.com/influxdb/v1.8/concepts/crosswalk/
- influxdb时间是一切
- infuxdb使用influxQL类似sql查询
- influxdb削弱更新和销毁能力,从而保证最快速的查询和插入,所以是CR-ud not CRUD
使用
influx https://docs.influxdata.com/influxdb/v1.8/tools/shell/ SDK https://docs.influxdata.com/influxdb/v1.8/tools/api_client_libraries/ WEB写入API https://docs.influxdata.com/influxdb/v1.8/guides/write_data/ WEB查询API https://docs.influxdata.com/influxdb/v1.8/guides/query_data/
什么时候使用influxdb
有个很重要的问题,什么时候可以用influxdb,怎么用
- 基于时间序列的查询或者分析
- 写多读少
- 无事务要求
创建数据库
influx方式
|
|
web api方式
|
|
查看数据库
influx方式
|
|
web api方式
|
|
写入数据的方式
influxdb把时间序列作为横坐标,纵坐标是在这个时间点的数据,可以为这个数据添加tag方便查询(tags被索引),保留这些数据结构field的 是measurement,类似于mysql的table。
|
|
删除数据库
influx方式
|
|
web api方式
|
|
influx方式
|
|
查询表
类sql的形式influxQL不再赘述,这里主要说下influxdb独有的flux方式,很有必要看一下哈
这里可以看一下网上介绍的influxdb架构图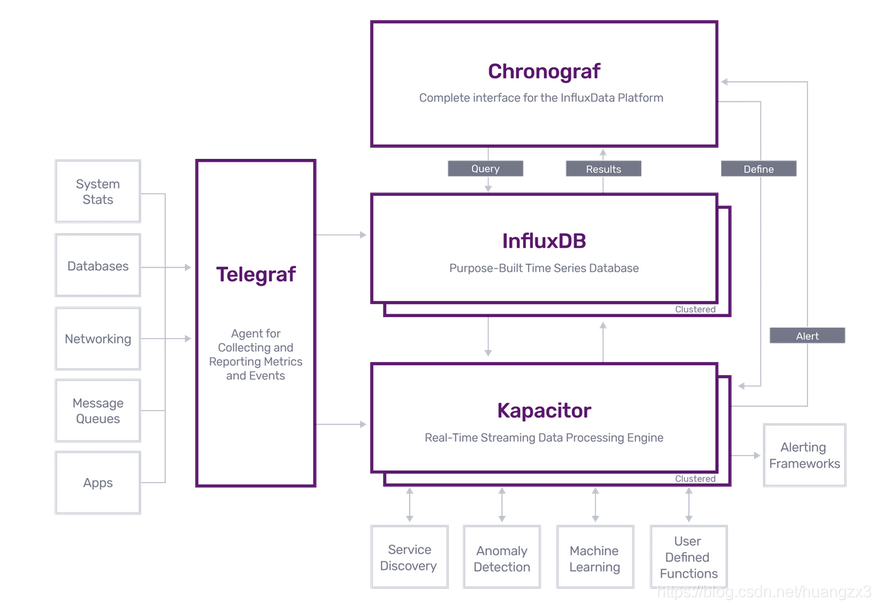 ◎ ../images/influxdb-structure.png
◎ ../images/influxdb-structure.png
flux语法
https://docs.influxdata.com/influxdb/v1.8/flux/
https://docs.influxdata.com/influxdb/v1.8/flux/get-started/
需要额外注意的是,默认flux是不开启的,需要这样开启https://docs.influxdata.com/influxdb/v1.8/flux/installation/
开启后是这样的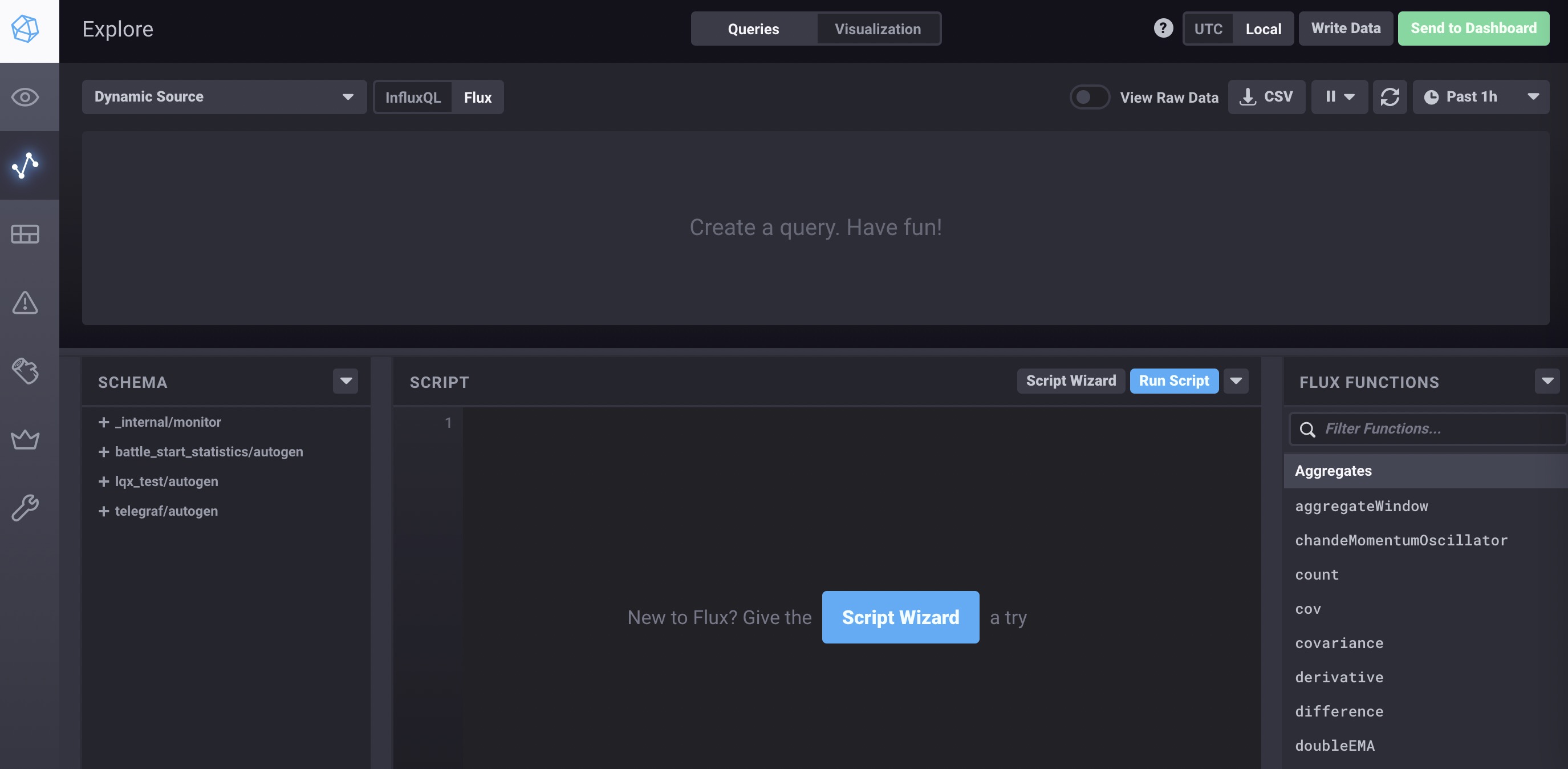 ◎ ../images/chronograf-influx.jpg
◎ ../images/chronograf-influx.jpg
一些概念concepts
桶,相当于database + retention policy
管道,数据流传递
每个分组group的共同值,这个组里面的每一行都是一样的
|
|
_time和_value不是,因为他们不是唯一的,每个row都不同, 具体可以看实际语法实操
install chronograf
https://docs.influxdata.com/chronograf/v1.9/introduction/installation/?t=RedHat+%26amp%3B+CentOS
|
|
这时候一般服务器本身会起8888端口,登录web http://xxx:8888 比较简单一路初始化下,最终可以在explorer页面
http://xxx:8888/sources/1/chronograf/data-explorer
 ◎ ../images/chronograf.jpg
基本看了下,chronograf是一个方便influxdb管理的web平台,类似elk的kibana,有如下功能
◎ ../images/chronograf.jpg
基本看了下,chronograf是一个方便influxdb管理的web平台,类似elk的kibana,有如下功能
- dashboard 有一个类似grafana的dashboard,可以新建并展示希望看到的数据,当然也可以让grafana展示
- alert 这个应该是需要kapacitor,支持告警通过编写alert rule,tick script根据influxdb告警,看了一下支持非常多的告警方式(命令,post,mail等等)
- 用户管理和连接管理 可以创建用户,可以通过8086端口管理多个influxdb
- 查询 explore功能,可以写influxQL或者flux,实现自己想要的查询
flux语法实操
官方的start文档 https://docs.influxdata.com/influxdb/v1.8/flux/get-started/query-influxdb/ 建议大家到chronograf里面的explore操作 对于flux包含几个部分 在这之前我在liuliancao的库里面插入了3条数据
|
|
|
|
紧接着用管道操作符号|>继续跟上时间戳
|
|
run script我们发现是有数据的
过滤我们的数据,继续跟上我们的管道|>,然后接上filter(), 这个filter里面放一个fn参数,里面是对应的过滤条件函数 这里其实条件可以用and or或者多个条件,注意图形界面可以通过选中字段并add filter实现
|
|
这个表达式最终获取的就是一条来自liuliancao的cpu measurement的host是lb0的load1的值
|
|
对应结果select load1, load15 from cpu group by region;
同一个measure相邻字段取差值并根据地区计算整体均值, 用influxQL很简单
|
|
用flux怎么写呢, 可以先看这篇不错的influxQL to flux文档 还有官方migration文档
|
|
整体用下来目前感觉还是有些时候需要琢磨,比如最简单的算下字段的AS,我认为flux处理的并不好,也可能是我没找到好的答案 如果没有chronograf也没问题,可以通过influx –type=flux进入flux命令行,用起来个人人为比较方便哈,决定更加深入的学习下这个dsl 先从语法开始吧 https://docs.influxdata.com/influxdb/v1.8/flux/get-started/syntax-basics/ 这里继续参考一个官方的例子
|
|
可以看出,flux可以实现类似编程和数据结构相关的方向,这一点是sql不具备的,把一连串数据保存下来,如何使用呢 继续参考官方的例子自己测试下 这里我直接404 page吐了,查看官方的issue发现,是bug,命令需要调整成
|
|
这样就不会404了 这里我有几个例子,大家可以看看
|
|
install kapacitor
|
|
官方git https://github.com/influxdata/kapacitor kapacitor is an Open source framework for processing, monitoring, and alerting on time series data. 可以看出kapacitor是做监控数据流处理和告警的。所以对应的是采集器,媒介等信息。 kapacitor使用一种DSL描述语言 TICKscript, 这里看官网的例子,可以看到这样定义结构非常清晰类似flux,我觉得这种解析方式不错,可以用在写的发布系统,哈哈
|
|
install telegraf
|
|
装完telegraf,在一开始配置chronograf的时候你可能默认选择了一些dashboard,没有页不影响
高可用
influx-proxy
|
|
然后看7076是否起来就ok了 但是这个方案不支持prometheus
influxb-relay
|
|
这样就可以实现一个简单的集群了,目前也不支持prometheus,有一个作者实现了这个,感兴趣可以尝试下
prometheus的折衷办法
写两份,读两份
|
|