Prometheus
Prometheus
Prometheus介绍
prometheus脱胎于brogmon(brog的监控程序), 是继nagios、zabbix、openfalcon等监控程序以来的最受大家欢迎的监控程序,以opentsdb为数据库,存储时序性信息,push通过pushgateway,其他主动通过pull,服务器段拉取, 通过强大的组件能满足多场景尤其是微服务化和虚拟化场景的需求。
什么时候选择它,什么时候不应该选择它
选择的原因
需要监控和告警时间序列的数据,比如http的响应时间等
zabbix其实也可以,但是zabbix用的mysql数据库,查询和保存都没有时序性数据库优化好
数据中心维度服务器监控和面向app的监控都可以,尤其是k8s类,希望对整体业务SLA等进行监控的
zabbix对app也支持,个人觉得不是很方便,目前来看更适合idc机房等
深入到系统内部进行监控,比如用到的核心中间件或者跟踪整个链路,并进行高强度的定制化,获得服务的真正运行状态
不喜欢客户端安装,强调可扩展性
prometheus默认不需要安装客户端,各个组件都是二进制文件直接可以运行不依赖环境
需要趋势统计和预测的,对于zabbix通常没有默认的预测模型和系统
promql语言强大,可以聚合等直接查询
不选择的原因
- 已经使用其他的监控方案,成熟使用并满足自身需求,或者团队具有自研监控 的能力
- 期待它完成日志性的东西并不适合
安装
安装比较简单,建议用源安装
注意有1和2版本,建议安装prometheus2
debian系:
|
|
rhel系:
|
|
yum -y install prometheus # 注意需要先导入源,具体请参考文末链接,但是有个错误$没转译,所以注意\$ yum -y install prometheus2 安装以后访问9090,注意打开安全组或者防火墙,界面非常简单,proms存储的是一组时间序列数据,目测和influxdb还是有点像,整体也是以metrics为单位
部署
prometheus自己的日志
这里发现所有的日志都进入到了/var/log/messages里面了,非常的不方便 这里有两个办法, 一个是设置StandardOutput=控制systemctl的output(但我设置了并没有成功),一个是设置syslog 这里我用syslog的办法 具体请参考Rsyslog
真正的自动发现
这个时候已经可以通过consul来告诉prometheus来直接连接metrics了,但是对于服务器来说, 希望能从cmdb里面拉取targets,这里有两个思路
这里其实可以放到cmdb里面集成,也可以linux定时任务操作
linux定时任务适合少量服务器场景
如果大量,设计到host增删改查的时候,适配下consul的部分即可,即把consul当成cmdb的一个核心组件,这个思路不错,
因为同样的,你还会用到它注册agent,所以针对consul我们可以设计很多好用的功能,让他系统和业务属性进行上报
否则让agent自己注册会发现agent根本不知道自己是谁,属于谁等等,而这,只需要在镜像中维护一个consul.json文件即可
但是还是要维护json,其实也比较麻烦,而且容易出错
而在各种metrics里面实现自己的信息,通常是监控指标,不建议放太多其他的类似日志的信息
可以看下这里的配置,具体不再演示 http_sd_config
http返回码需要200,Content-Type为application/json 返回样式为
|
|
组件框架和结构 (参考https://www.prometheus.wang/quickstart/prometheus-arch.html)
官方架构图
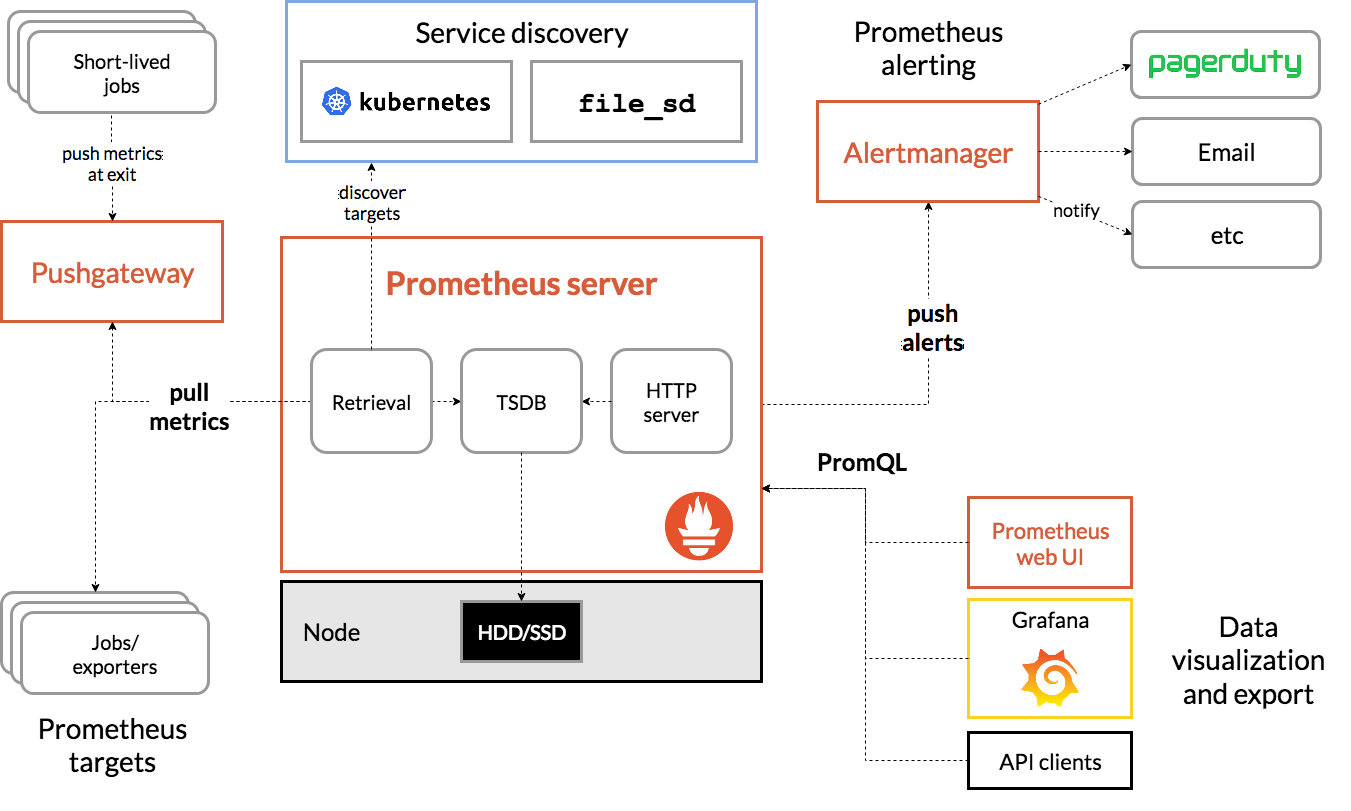 ◎ ../images/prometheus-architecture.png
◎ ../images/prometheus-architecture.png
架构介绍
可以明显看出来如下:
- 服务器的信息会被prometheus主动从exporter pull(采集)过来
- 如果不能pull的就通过一个push gateway的一个代理,让服务器定期上报到gateway,然后服务器从代理pull(采集)过来
- 通过alert manager发送告警信息
- 前端可以通过promql查询opentsdb的数据,当然为了可视化,可以通过grafana、Promdash等可视化工具,可以做的非常方便漂亮,毕竟prometheus的界面…
- 和zabbix类似,有自己的auto discovery模块可以自动发现服务和服务器
- exports提供专门http端口负责专门的软件信息收集
prometheus使用
参考官文https://prometheus.io/docs/prometheus/latest/configuration/configuration/
prometheus service配置
prometheus.yml配置
|
|
注意一下内容:
- 几个端口9090 9093 9100分别是什么含义
- 如何自定义rule和自动以config
通过自己写rules.yaml包含在里面
- 默认pull的间隔是15s,如果自己要改可以在job_name下面覆盖掉
采集exporter
exporter列表
每个exporter其实是一组采集器,采集和上传数据, 可以看到有很多的exporter,
常见的第三方exporter https://github.com/prometheus/docs/blob/main/content/docs/instrumenting/exporters.md
|
|
安装linux监控
node_export github node_export 官网
|
|
基本上按照上面操作一下,web界面过一会就会有node开头的metric了
安装windows监控
使用https://github.com/prometheus-community/windows_exporter releases下载地址 安装,然后prometheus服务器加上9182的配置即可 安装好以后会出现一个windows_exporter的服务, 这个时候telnet windows_ip 9182看是否通 如果不通检查防火墙和安全组, 然后reload 此时看http://xxx:9090/targets 发现服务器up了 systemctl reload prometheus
配置黑盒监控
从用户角度,用一个探针看一个链接或者端口的延迟等信息, 具体可以参考黑盒exporter github 直接安装就好了,没有安装参考前面的promethes.repo设置,配置不难,如果需要检查和content相关可以参考 官方给的示例 https://github.com/prometheus/blackbox_exporter/blob/master/example.yml fail_if_body_not_matches_regexp, 具体不再演示
|
|
资产targets
安装consul
prometheus配置consul
|
|
这个时候consul注册上来的带有xxx的标签的服务器才会被选中, 在consul注册的逻辑里面,我们可以加入丰富的业务逻辑,来方便识别和告警 这里需要明白: node服务器本身不需要配置,只需要管理服务器直接代其注册到consul,prometheus会做具体的连接和监控 所以我们先把之前的windows和linux的配置注释掉,然后在管理机器上执行如下命令测试下consul连接情况
配置时候还是起不来 Get http://172.16.27.71:8300/metrics: read tcp 172.16.27.71:42006->172.16.27.71:8300: read: connection reset by peer
其实这个是正常的,因为他没有metrics这个api,惊不惊喜,哈哈
先向consul里面塞一条node的数据
curl -XPUT -d '{"id":"test1", "name": "node-exporter-172.16.27.71", "address":"172.16.27.71", "port":9100,"tags":["liuliancao.com"],"checks":[{"http":"http://172.16.27.71:9100/metrics","interval":"5s"}]}' http://localhost:8500/v1/agent/service/register
(如果不加relabel和services的限制)塞完以后发现当前node exporter是ok的,而他的数据都是metrics形式展示出来
 ◎ ../images/prometheus-consul1.jpg
◎ ../images/prometheus-consul1.jpg
这里一定要注意,在prometheus里面services选项一定要填name对应的值,为了避免有问题,建议id和name保持一致哈,否则会一致没注册上来
注意这里
- 可以加很多个主机的exporter,每个可以分属不同的service或者带自定义参数
- 可以让开发或者部署脚本的地方加入consul加入和移除逻辑,这样,整个链路就是自更新的
- 可以自己写一些符合metrics的api,放到这里面就是一个监控项目
- 创建服务器的时候,向consul里面插入一条监控数据,销毁的时候,从consul里面deregister这个服务
最终配置
|
|
整体下来会发现,prometheus提供了一个空间,这个空间填我们要测试的数据的api接口,对他们进行汇总和统计
promql
参考https://www.prometheus.wang/promql/
metrics
prometheus的数据和grafa匹配 指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)
了解metrics的data model
具体可以看下 https://prometheus.io/docs/concepts/data_model/ 和 https://prometheus.io/docs/practices/naming/ 一条metrics里面的信息如下 <metric name>{<label name>=<label value>, …} 这样比较抽象,我们可以看下linux的node_exporter的10条信息
|
|
如果了解influxdb的应该很快就可以看出来(不了解可以看下我的influxdb文章),这个和influxdb的太像了, 我们可以对应下 第一个值是一个字符串,字符串里面可以写labels,label是加索引的,方便根据label查询, 后面跟上值即可
这里我们可以根据最佳实践注意几个问题 metric name
- 不要用无意义字符,建议就字母数字加_,不要用太奇怪的
- 有一个应用前缀,比如redis_read_qps_all
- 最好要有单位 比如redis_read_latency_seconds
labels里面不要再用metric里面的字段了,容易产生歧义
counter
计数器,只增不减除非发生重置,比如请求量等
gauge 可增可减的仪表盘
比如可用内存等
histogram && summary
分析历史数据,比如0-2ms的时间请求量,2ms-5ms的时间请求量,并对之进行汇总统计
获取指定名称的数据 可在http://192.168.10.204:9090/graph?g0.range_input=1h&g0.expr=promhttp_metric_handler_requests_total&g0.tab=1 测试
http_requests_total http_requests_total{}
=和!=都支持
http://192.168.10.204:9090/graph?g0.range_input=1h&g0.expr=promhttp_metric_handler_requests_total%7Bcode%3D%22500%22%7D&g0.tab=1 http_requests_total{node="500"}
支持正则
http://192.168.10.204:9090/graph?g0.range_input=1h&g0.expr=promhttp_metric_handler_requests_total%7Bcode%3D~%22500%7C200%22%7D&g0.tab=1 http_requests_total{node=~"500|200"} http_requests_total{node!~"500"}
范围查询
http_request_total{}[5m] 最近5分钟的数据http://192.168.10.204:9090/graph?g0.range_input=1h&g0.expr=promhttp_metric_handler_requests_total%7Bcode%3D~%22500%7C200%22%7D%5B5m%5D&g0.tab=1
时间位移查询
http_request_total{} offset 5m 5分钟前的瞬时数据 http_request_total{}[1d] offset 1d 昨天一天的数据
聚合
常用的聚合函数 sum (求和), min (最小值), max (最大值), avg (平均值), stddev (标准差), stdvar (标准差异), count (计数), count_values (对value进行计数), bottomk (后n条时序), topk (前n条时序), quantile (分布统计) 聚合的语法 <aggr-op>([parameter,] <vector expression>) [without|by (<label list>)] example sum(http_requests_total) without (instance) sum(http_requests_total) by (code,handler,job,method) sum(http_requests_total) count_values("count", http_requests_total) topk(5, http_requests_total) 前五位排序 quantile(0.5, http_requests_total) 计算分布情况 0.5是中位数
内置函数
increase
返回增长量
rate
返回增长速率
irate
返回增长速率,更准确强调瞬时变化率, 但不适合长期计划速率波动的情形
predict_linear
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
标签替换
label_replace(up, "host", "$1", "instance", "(.*):.*") 意思是替换up的instance变量的:前的第一个值捕获,放到host标签中
HTTP api调用
可以通过/v1/api调用
删除某个series
注意此操作不可逆,确认ok以后再进行操作
|
|
PushGateway
默认proms是pull拉取服务器的监控数据的,如果由于nat等情况导致收集不上来,可以通过安装push gateway做一个中转,服务器先把数据发到push gateway里面,gateway再转发到proms server
可以通过把数据通过POST方式上传到Pushgateway,prometheus收集pushgateway即可
|
|
推送数据
|
|
如果报错,尝试在test_data后面继续加入维度比如/$host
Alertmanager
安装
|
|
使用
建议先阅读一遍 Prometheus alertmanger官方配置, alert分为几个部分 这里先看官方的一个示例
|
|
可用看到alert manager的配置主要是route、matcher、receiver的配置, 了解几个术语
route
对应要对哪些业务告警,比如以服务维度,或者集群维度
matcher
匹配的逻辑是什么,service,关键词,tag等等 这里有个问题,就是我有多少告警并不知道
amtool
目前可以通过下载amtool解决(默认release自带) 如果没有请手动安装
|
|
然后访问查看alert列表
|
|
这里建议设置下默认的配置,这样不用每次输入url
|
|
这里为什么是空呢,因为alert rules还没有配置
promtool
|
|
记得reload下,这里需要注意一个问题promtool check rules如果你检查一直失败也没关系,需要注意下prometheus的版本,
如果yum装的是prometheus是1.8版本,yum -y install prometheus2则是2.0版本,建议安装2.0版本
因为这个时候写的是rules,是prometheus的东西,这里提示我们看文档一定要注意版本,否则就安装最新版
此时http://your_prometheus:9090/alerts 就可以看到对应的alert了,如果你有一个consul是down的,那么就会有一个pending的
 ◎ ../images/prometheus-alert0.png
过2分钟以后变成fire状态
◎ ../images/prometheus-alert0.png
过2分钟以后变成fire状态
 ◎ ../images/prometheus-alert2.png
这个时候检查alertmanager的日志,发现tls没有配置,这个时候为了简单,我把tls关掉了,后续需要修掉使用tls会更安全
这里有篇文档参考https://docs.oracle.com/cd/E19120-01/open.solaris/819-1634/fxcty/index.html 或者考虑后续换个发邮件
alertmanager.yml里面增加了一行smtp_require_tls: false
◎ ../images/prometheus-alert2.png
这个时候检查alertmanager的日志,发现tls没有配置,这个时候为了简单,我把tls关掉了,后续需要修掉使用tls会更安全
这里有篇文档参考https://docs.oracle.com/cd/E19120-01/open.solaris/819-1634/fxcty/index.html 或者考虑后续换个发邮件
alertmanager.yml里面增加了一行smtp_require_tls: false
告警配置多个人
只要写多个to就好了,且多个configs就好了
|
|
告警rules
rules配置
这里以consul是否up为例, 其他例子请参考awesome-prometheus-rules
|
|
告警媒介
媒介测试
所有的媒介可以在这里看到 alertmanager媒介列表 配置完了alertmanager可能不知道是否生效,比较好的办法是直接调用api 官方github有alertmanager example 这里可以直接运行哈,一般建议运行9093的test就好了
aliyun企业邮集成
配置供参考
|
|
最终发现能收到邮件了哈 [[../images/alertmanager01.png ]]
dingTalk集成
|
|
可能会觉得graph的链接有问题,比如是你的主机名,这个时候需要修改prometheus的启动参数,默认在/etc/default/prometheus如果没有直接加在命令行也可以
|
|
最终效果是这样的哈
 ◎ ../images/dingtalk01.png
◎ ../images/dingtalk01.png
dingding集成
dingtalk使用起来,常常会丢告警,还是有一些问题,用python实现了一个简单的模块
https://github.com/liuliancao/alertmanager-dingding
需要一个dingding机器人和dingding h5应用,支持dingding单发,webhook群发,告警抑制2h,图表关联等
模板优化
参考官方文档自定义模板 主要注意几个东西哈 $label包含标签相关的内容,比如 $label.alertname $label.instance $label.job $label.member $label.monitor 这个是相对的,具体和metrics相对应 $value是实际metric的值 我们可以针对rule进行自定义description和summary
|
|
标题等相关的内容需要通过进一步了解Go Template和如何进行模板设置来说, 一个操作就是把prometheus重新go build一下,修改对应的default.html, 另一个办法是找是否有对应的参数可以设置,目前我还没找到哈, 大家觉得有必要可以继续深究,有空我可能会补上
用了prometheus发现原来类似zabbix或者云监控的那些告警咋都没了,怎么办呢,其实有很多共享rules的地方 在写的时候要注意下 开头必须是这样的,否则会报没有group的错误, 写完记得check rules一下
|
|
正确的开头
|
|
发现还是有个问题,我consul_sd发现的服务存在这样的问题,对应的service是0
up{instance="172.16.27.79:81", job="ecs-monitor", notice="xxx proxy server"} 0 up{instance="172.16.27.80:81", job="ecs-monitor", notice="xxx proxy server"} 0
而对应的node_exporter的service是1,这个很奇怪
up{instance="172.16.27.79:9100", job="ecs-monitor", notice="linux server"} 1 up{instance="172.16.27.80:9100", job="ecs-monitor", notice="linux server"} 1
其实这里要明白一个问题, consul_sd终究是配置了service discovery的地方,所以只是变相把各个服务器的service报到了master上面,
所以看一个服务是否up其实就是server或者client对对应端口是否有访问权限,如果访问不通肯定不行,更别谈metrics
经过检查, 我发现prometheus到对端81端口并不通,开放安全组看下, 还是不行, 发现是不是没有/metrics url导致的
结果用nginx 测试了一下,发现还真是
所以总结下
- consul自动发现发现的服务需要能访问$INSTANCFE_IP:$SERVICE_PORT/metrics能够被访问, 并且有up = 1这个metrics才行
- 如果不是这样,就不要用up这个监控项, 可以用 consul_catalog_service_node_healthy配合service_name来检查服务状态
高可用相关
联邦集群
联邦集群的设置, 联邦集群的关系是这个集群会有其它targets的数据
|
|
如果服务无法启动,可以通过journalcel -xe或者journalctl -u prometheus查看,最终结果就是targets里面有我们对应的federate了
可以发现,是从别的prometheus服务器获取信息,那么
- 可以做备份
- 可以做区域-网关的结构,一个prometheus去多个prometheus获取,这样可以均衡metrics的压力
联邦集群是一种冗余方式,只要互相配置联邦集群,数据保存在本地也是可以
多写数据库
|
|
这样的弊端是滚动需要数据库进行设置,且可能存在丢数据的情况
实际监控项目
网络
监控ping和拨测延迟
smokeping
https://github.com/SuperQ/smokeping_prober
https://grafana.com/grafana/dashboards/11335
blackbox
blackbox.yml
|
|
test.json
|
|
双向tracert
一个定时任务,把双向tracert信息吐到elasticsearch
|
|
云数据接入
aliyun
https://github.com/aliyun/aliyun-cms-grafana/releases/tag/V2.1
wget https://ghproxy.com//https://github.com/aliyun/aliyun-cms-grafana/releases/download/V2.1/aliyun_cms_grafana_datasource_v2.1.tar.gz https://help.aliyun.com/document_detail/313842.html?spm=5176.21213303.J_6704733920.10.30a153c93VQ97X&scm=20140722.S_help%40%40%E6%96%87%E6%A1%A3%40%40313842.S_hot%2Bos0.ID_313842-RL_grafana%E5%AE%89%E8%A3%85cms-LOC_helpmain-OR_ser-V_2-P0_1
tencent
https://cloud.tencent.com/document/product/248/54506 grafana-cli plugins install tencentcloud-monitor-app
中间件
logstash
|
|
grafana dashboard https://grafana.com/grafana/dashboards/12707
puppet(>=5.0)固化
|
|
elasticsearch
elasticsearch_exporter https://github.com/prometheus-community/elasticsearch_exporter 要注意修改下默认的service文件
|
|
然后在https://grafana.com/grafana/dashboards/?search=elastic 页面搜索elasticsearch,找到合适的进行导入即可
缺少哪些在github里面添加对应的参数即可
如果不出现instances和集群等图表,图表一直是空的话,记得检查下elasticsearch_exporter的参数
没有exporter的一种方案
grafana相关
更多请看下面链接,没有prometheus ui的可以了解一下grafana 8.x以后的unified alerts Grafana
列出所有标签的值
grafana https://grafana.com/docs/grafana/latest/datasources/prometheus/#templated-queries
label_values(metric, label)
关闭告警
http://xxx:9093/#/alerts 一般来说有告警的话,会有
但是matcher可能无从下手,请参考文档https://prometheus.io/docs/alerting/latest/configuration/#matcher
比较常用的是 alertname 和rule里面的name一致 instance 和你的告警模板一致
web集成
夜莺的测试和使用
docker安装参考https://developer.aliyun.com/mirror/docker-ce?spm=a2c6h.13651102.0.0.3e221b115bonZp
夜莺安装参考文档 https://n9e.github.io/docs/install/compose/
github位置https://github.com/ccfos/nightingale
docker-compose up -d我报错了
|
|
我直接platform注释掉了
最终就正常启动了,具体端口如下
|
|
服务启动之后,浏览器访问nwebapi的端口,即18000,默认用户是root,密码是 root.2020
 ◎ ../images/nightnale.png
◎ ../images/nightnale.png
还是集成了不少功能的,比如如果用prometheus,可以不用alertmanager部分, 个人对代码即配置比较感兴趣,这里并不是很方便。web方便做的还是挺好的, 有对应的大盘等,这个我是准备自己开发。
kafka
mysql
https://github.com/prometheus/mysqld_exporter
|
|
注意.my.cnf要设置好密码用户名等
|
|
注意多实例不是在.my.cnf配置的 直接在prometheus job配置即可 参考官方的 github https://github.com/prometheus/mysqld_exporter
|
|
还有一种思路如果是云上的,可以导入grafana云监控插件(各个云一般都支持), 然后接入他们的metrics
mha监控,部分部署了mha manager,这个时候需要监控下这个进程,检查 node_exporter实现比较麻烦,发现process_exporter支持
|
|
mongodb
https://github.com/raffis/mongodb-query-exporter
|
|
redis
ntp time
关于ntp监控,我建议监控2个指标
指标1: ntpd是否正常 node_exporter开启此参数 –collector.ntp 表达式 node_scrape_collector_success{collector="ntp"} != 1
指标2: ntpd是否同步正常 表达式 node_timex_sync_status != 1
如果对于时间差异比较敏感一方面可以调整ntp.conf增加maxpoll设置 设置为2 的4次方到14次方之间
或者添加ntpdate相关的crontab任务 定期同步
relabel config
比如node_exporter去掉指定端口
|
|
预测
predict_linar holt_winters 不过这个没看到哪里有写怎么用
坑
默认保存天数是15d,建议改成更多的天数方便查看
/etc/default/prometheus添加即可
|
|
metrics编写go版本
建议阅读官方文档和github的源码 https://pkg.go.dev/github.com/prometheus/client_golang/prometheus#Collector
几个exporter的代码都可以借鉴一下 https://github.com/treydock/ssh_exporter/blob/master/collector/collector.go https://github.com/Lusitaniae/apache_exporter/blob/master/collector/collector.go
建议使用collect的方法。
collect.go
|
|
exporter.go
|
|
参考链接
- yum安装
- exporter列表 https://github.com/prometheus/docs/blob/main/content/docs/instrumenting/exporters.md
- prometheus官方文档
- prometheus使用
- prometheus操作指南
- prometheus添加consul自动发现
- prometheus relabel
- prometheus所有配置
- 联邦集群
- 高可用文章
- grafana可视化
- https://prometheus.fuckcloudnative.io/
- https://www.prometheus.wang/
- https://www.kancloud.cn/cdh0805010118/prometheus/719340
- Prometheus alertmanger官方配置
- alertmanager example
- 自定义模板
- alertmanager媒介列表
- 一个prometheus多idc的google讨论
- awesome-prometheus-rules
- 关于prometheues的告警interval等各种配置
- 常见的auto discovery方式 https://prometheus.io/docs/prometheus/latest/configuration/configuration/#http_sd_config
- prometheus labels explanation
- 关于promql不错的教程